Node properties and the EAV pattern
Evolving past the forum roots and building a wiki style knowledge base feature (which was actually apparently part of the plan since the start, which I recently discovered) led to the Library materialising as a core, almost flagship, feature of Storyden.
MediaWiki has this concept of "info boxes" which display basic attributes about the topic. They are present on almost every medium to large Wikipedia page and often link out to broader category pages such as locations, years, genres, styles, people, companies, etc.

These are essentially relations, in a big graph. However, the way MediaWiki implements them is just another piece of content on the page. If I click "dreampunk" in the above infobox for British-American vaporwave duo, 2814 (to which much of the Storyden code was written) I land on the Wikipedia page for the dreampunk music genre, and on that page is a backlink to 2814 somewhere in the content.
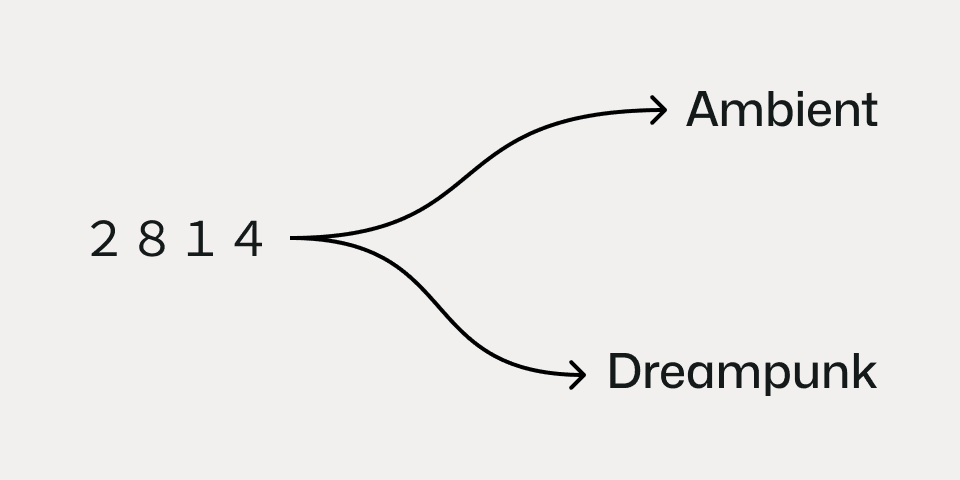
Where this breaks down a bit is when I click the "ambient" link and land on the Wikipedia page for the ambient genre. There is no backlink to 2814. This is because those relationships are defined at the hypermedia layer. If I wanted to build a graph analysing the relationships between 2814 and their associated genres, similar acts, related people, etc. I would need to parse the content itself as the underlying relationships are not expressed in any other way.
Finding all the artists under "ambient" would not be possible solely from the "ambient" Wikipedia page; I would need to essentially scan every single Wikipedia page that exists and filter for those that have "ambient" in their "Genres" infobox.
Those of you who know relational database query planners would identify this as a "full table scan" as opposed to an index scan.
It's worth noting that this observation is not a problem for Wikipedia, its purpose is not to perform analytical processes on the knowledge graph, its purpose is to provide a free and open source of crowd-sourced and fact-checked information. One of the most important endeavours of our modern society.
For Storyden, we wanted to avoid having relationships buried in free text and instead make them first-class data citizens.
Entity-Attribute-Value
(not to be confused with Entity-Component System)
Storyden's goal is to make a community's collective knowledge organised, searchable and discoverable. Whether that's through discussion, curation or collection.
(the precursor to this was an indie fashion directory called Threadbase I started to build in 2018, but that's a story for another day!)
This made a relation graph an attractive concept to build in, something that did not exist in most "wiki" platforms. A big inspiration was Notion's "database" feature, where pages in the tree can exist within a structured table where attributes of the page itself become columns in that table. Essentially creating a very user-friendly relational database.
So how do you implement a relational database inside a relational database?
There are two ways to do this:
-
Actually just surface the relational database itself as an API.
This approach means that when you add a property to a page the application runs an
alter table add columncommand against the database. Your database table structure is the user's interface into the properties and relations within the content itself. -
Implement an entity-attribute-value pattern
The approach Storyden takes, where an additional table stores property names and values which are then related to the actual pages.
Notion seems to use a hybrid of both approaches where SQLite acts as a relational cache with a "real" schema, then the cloud persistence implements some flavour of EAV. When you load a Notion page, the property queries run on the fast SQLite instance after the bulk of the data is loaded from the cloud store.
Storyden is much simpler and just has one database: SQLite or PostgreSQL, whichever floats your boat. And on-the-fly schema modifications sound complex and could make migrations a nightmare. So I opted for EAV.
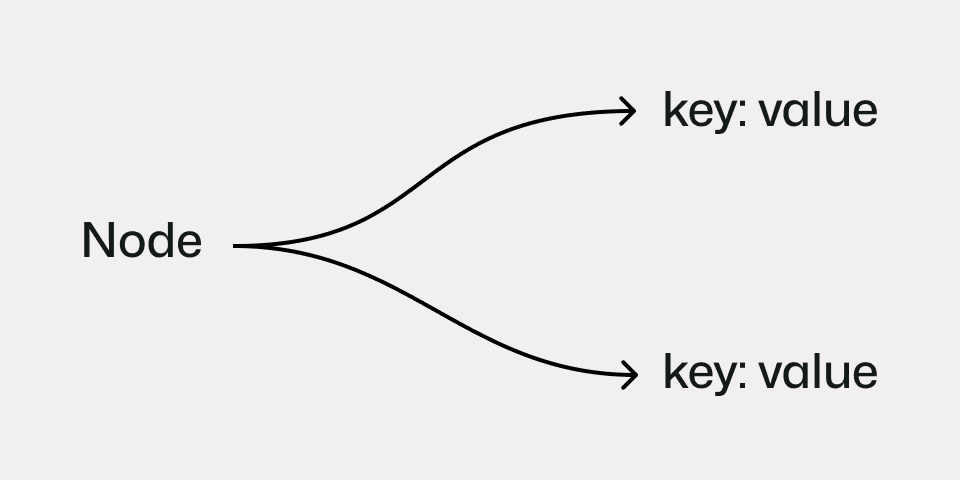
Now, while the EAV pattern offers flexibility without needing to keep tabs on the underlying database schema, it comes with tradeoffs. Both of these databases are heavily optimized for relational queries over fixed-column schemas, where indexes, statistics, and query planners can make efficient decisions based on known, static table structures.
With EAV, the key-value nature of the data model complicates what would normally be a simple column filter or join into multi-table joins and lookups.
For example, to sort a set of nodes that represent companies by their founded_year, it can’t use a direct index scan on a founded_year column, it would need to join the properties table to find the correct key and then filter or sort on the resulting rows. This makes it difficult for the query planner to optimize because the database cannot prebuild indexes across what are effectively row-based dynamic fields.
As with any technical decision, there are compromises. I chose EAV because it was (somewhat) easier to implement for now. I am but a sole developer and this product is not a money-maker, I don't have a team of people smarter than me (that would be great!) so I've chosen a dumb solution. If I had chosen a dynamic schema approach, it would have increased the testing surface area massively, and a bug in that kind of system carries a higher risk. I chose low risk at the cost of slightly reduced performance.
Properties today
As of this post, the API is almost fully implemented, it only lacks data type implementations (which is a challenge in and of itself, given every cell is just a text type) so if you're a user of the API only, you can take advantage of this now!
The Storyden frontend currently exposes properties as a basic table on Library Pages. Table views, filtering and other features are on the near-term roadmap so keep an eye out!
What's next?
Now that this feature has landed in the API side, I have big plans for the knowledgebase side of Storyden's product offering. This unlocks:
- Database tables, like Notion but social!
- Big directories that are easy to navigate, filter and search
- Pre-filtered views of database nodes, referenced in other pages
Who is this for? Some ideas themed on early adopter feedback sessions:
- Video game communities who want to keep track of item stats in a structured way
- Curators who want to maintain a community contributed directory of resources
- Gear nerds who want to catalogue their favourite tools, devices, etc.
Technical overview
If you came here for the details, here's how Node Properties are implemented.
Library Pages are a tree structure, so internally they are called "Library Nodes". Being a tree structure, this means each node may have many children. When properties come into play, this means all children of a given node must share the same set of possible properties. Properties are organised into "property schemas" to ensure this fact.
In data modelling terms, this means for every group of nodes with an identical parent_node_id the property_schema_id must be also identical. So all the nodes with some parent A, also must use the schema X
The schema itself may have fields, fields are defined once to save space and make changing field names or types easy. This means that a node has one schema and that schema has many fields.
Property values are stored separately from the underlying property schema, because each node in a set will have many property values, each value maps to a schema field. This means that a node has zero or many property values but always zero or one schema.
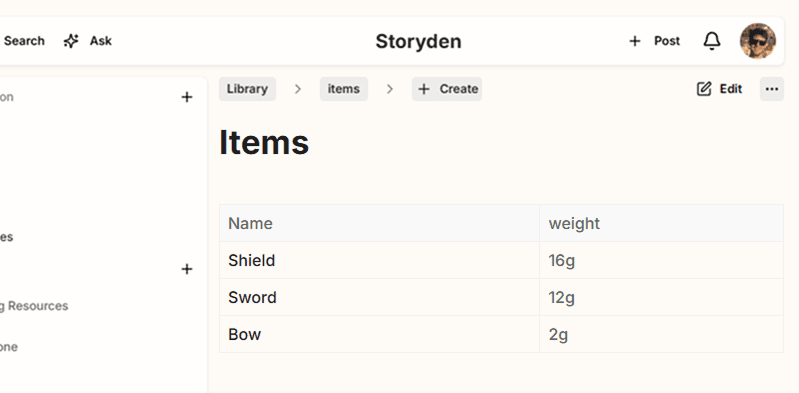
Other than the schema itself, properties are quite loose, a set of children may hold a subset of property values. For example, given 3 nodes under "Items" only one or two of those nodes may have a property value for "Weight".
Some query use-cases
These excerpts from the Storyden source code are dated 10th of May 2025, in the event these change, check out the latest source code.
An API consumer will care about a few different perspectives of this data structure. For example, you may want to get a single node without its children and see its "child node schema". This would be the schema that all child nodes of that schema share. This "child node schema" is not actually stored on the parent node itself because root nodes have no parent and this would restrict the ability for root level nodes to have properties. For this reason, the schema itself is referenced by the nodes directly, allowing root level nodes to hold a schema and properties.
Querying property schemas of nodes
To solve this use-case, the siblings and the parent are queried to gather all fields. So if the parent node also has a schema, you get both in one query:
with
sibling_properties as (
select
ps.id schema_id,
min(psf.id) field_id,
min(psf.name) name,
min(psf.type) type,
min(psf.sort) sort,
'sibling' as source
from
nodes n
left join nodes sn on sn.parent_node_id = n.parent_node_id
inner join property_schemas ps on ps.id = sn.property_schema_id
or ps.id = n.property_schema_id
inner join property_schema_fields psf on psf.schema_id = ps.id
where
n.id = $1
group by ps.id, psf.id
),
child_properties as (
select
ps.id schema_id,
min(psf.id) field_id,
min(psf.name) name,
min(psf.type) type,
min(psf.sort) sort,
'child' as source
from
nodes n
inner join nodes cn on cn.parent_node_id = n.id
inner join property_schemas ps on ps.id = cn.property_schema_id
inner join property_schema_fields psf on psf.schema_id = ps.id
where
n.id = $1
group by ps.id, psf.id
)
select
*
from
sibling_properties
union all
select
*
from
child_properties
order by source desc, sort ascAnother use-case is you pull one node that's a child of a parent node. You want to see this node's schema and its values. This one is easy, the schema is already stored on the node itself so it's just a quick join against properties of that node - which is a direct relationship. However, because the properties themselves only store the values of properties, the schema and schema fields are still required in the query. Values are related to schema fields by the field ID.
Some useful observations for schemas and values:
- Schemas don't change often, usage patterns often see rare but relatively large bursts of mutations (when a user is setting up a new page or editing columns) followed by no changes for a while. This allows caching to come into play and this is easy to implement over the top of the current node repository as properties are queried separately, not joined against the node itself.
- While schema data involves some pretty gnarly queries, the sizes of actual schemas are in the 10s of rows.
- The actual bottleneck is in the node queries themselves, where parent nodes may contain hundreds or thousands of children so more work on optimisation will focus on these read paths rather than property value/schema write paths.
Sorting nodes by their EAV values
One of the more complex and performance sensitive areas is querying all children of a node and operating on the property values to perform filtering or sorting. This is currently implemented as a separate query to pull the properties in a table result and joined in-application to the nodes being queried. The sorting itself is still performed in the database when pulling the property values. The ordered result is then used to sort the list of nodes in-application while mapping the results to the nodes.
const querySortedByPropertyValue_sqlite = `
select
n.id id
from
nodes n
left join properties p on n.id = p.node_id
inner join property_schema_fields f on p.field_id = f.id and f.name = $1
where
n.id in (%s)
order by
case f.type
when 'text' then p.value
when 'number' then cast(p.value as real)
when 'timestamp' then cast(p.value as datetime)
when 'boolean' then cast(p.value as integer)
else p.value
end %s
limit %d
offset %d
`
const querySortedByPropertyValue_postgres = `
select
n.id id
from
nodes n
left join properties p on n.id = p.node_id
inner join property_schema_fields f on p.field_id = f.id and f.name = $1
where
n.id in (%s)
order by
case f.type when 'text' then p.value end %s,
case f.type when 'number' then cast(p.value as numeric) end %s,
case f.type when 'timestamp' then cast(p.value as timestamp) end %s,
case f.type when 'boolean' then cast(p.value as boolean) end %s,
p.value %s
limit %d
offset %d
`In classic SQL-doesn't-have-a-standard-that-anyone-cares-about fashion, we need two separate queries here, one for PostgreSQL/CockroachDB and another for SQLite.
Another irritating fact is you can't parameterise anything in a query, only certain types of syntax so certain parts of this query must be (dangerously) injected using string formatting primitives before being passed to the database's own argument mapping. So there's a mix of $ positional arguments and % format specifiers. It'll probably stay this way for the next 50 years so don't hold your breath for improvements...
Okay, ranting aside, this query gets us a list of node IDs sorted by the given property value, based on its declared data type. The case-switch in the order by clause allows us to lexographically sort text while correctly sorting other types such as numbers, timestamps and booleans.
Pulling the whole tree while filtering nodes with many children
This use-case of "database nodes" that hold many children that looks somewhat like a relational database on the surface introduces another problem. Storyden's sidebar will give you the whole tree, and if one of those nodes has 1,000 children because it's being used as a "database page" with a bunch of properties rendered as a table, that's a problem.
So, to solve this, nodes have a column called hide_child_tree which, when true, will omit the children of that node (not the node itself) from the tree. This means the node that contains 1,000 children will still be visible in the sidebar, but its children will not and React will not try to render thousands of DOM nodes.
This is achieved by checking the hide_child_tree in the recursive part of the tree-traversal recursive CTE. What this does is it tells the query engine to stop recursing once that clause yields a false outcome resulting in the immediate row being emitted but none of its children will be iterated and the query continues to the next sibling to continue walking the tree.
with recursive children (parent, id, sort, depth) as (
select
parent_node_id,
id,
sort,
0
from
nodes
where %s
union
select
d.parent,
s.id,
s.sort,
d.depth + 1
from
children d
join nodes parent_node on parent_node.id = d.id
join nodes s on d.id = s.parent_node_id
where
parent_node.hide_child_tree = false
)
select
distinct n.id node_id,
n.account_id node_account_id,
n.visibility node_visibility,
n.sort node_sort_key,
depth
from
children
inner join nodes n on n.id = children.id
inner join accounts a on a.id = n.account_id
-- optional where clause
%s
order by
depth, node_sort_keyAgain, <SQL rant />, %s is there at the bottom to dynamically inject more clauses to the query. No injection here as the rest of the code that constructs this query inserts $ positional arguments and passes the user-supplied fields into the database's arguments not the raw string query. The code is a mess, please don't look for it.
Conclusion
It works. It's not perfect, and it is begging for improvements but it works. And it has fairly deep end-to-end test coverage so that's a win!
If you'd like to contribute to this mess, please check out the project's GitHub page! https://github.com/Southclaws/storyden
Back to index
